

A Developer's Guide to Event-Driven Architecture with Kafka
# Unpacking Event-Driven Systems: A Journey Through Kafka, Coupling, and Collaboration
I've recently been reading "Designing Event-Driven Systems" by Ben Stopford (a book from Confluent), and it has crystallized many concepts about how modern, scalable systems are built. This post is a summary of my key takeaways, exploring what Kafka truly is, how services communicate, and the powerful patterns that emerge in an event-driven world.
## What is Kafka? (And What It Isn't)
It's easy to pigeonhole new technology by comparing it to what we already know. Kafka often gets compared to two familiar tools: Enterprise Service Buses (ESBs) and Databases. While it shares some characteristics with both, Kafka is fundamentally a **streaming platform**, a different beast altogether.
### Kafka vs. Enterprise Service Bus (ESB)
Like an ESB, Kafka is great at moving data between different systems. It can pull from a wide variety of sources, transform data, and push it to many destinations. But the similarities end there.
* **Architecture:** Traditional ESBs are often centralized, monolithic systems. Scaling them beyond a single machine is difficult and often not a core design feature. Kafka, on the other hand, is decentralized and designed for horizontal scalability from the ground up.
* **Philosophy:** ESBs often follow a "smart pipes, dumb endpoints" model. The central bus contains all the business logic, and a central team manages it. This creates a bottleneck, slowing down changes. Kafka flips this to "dumb pipes, smart endpoints." Kafka itself is just a resilient, scalable log. The business logic lives in the services that produce and consume data, allowing for decentralized ownership and faster development cycles.
### Kafka vs. Database
Like a database, Kafka offers durable storage, a query language (KSQL), and even support for transactions. But its purpose is different.
Databases are optimized for storing **data at rest**. They excel at complex queries and managing the current state of information. Kafka is optimized for **data in motion**. It's designed to handle continuous, high-volume streams of events, making it the backbone for real-time applications.
## The Core of Kafka: The Distributed Log
So, what makes Kafka so powerful? It all comes down to its core abstraction: a partitioned, replayable, append-only log.
1. **Append-Only Log:** Kafka stores messages sequentially in what it calls a "topic." Because both reads and writes are sequential disk operations, they are incredibly fast and efficient, allowing for batching, caching, and prefetching.
2. **Scalability:** A topic is broken down into partitions. These partitions can be distributed and replicated across many machines. Need more throughput? Just add more machines to the cluster and rebalance the partitions. This architecture makes it virtually impossible to hit a scaling limit.
3. **Ordering Guarantees:** Kafka provides a strict ordering guarantee for messages *within a single partition*. If you need global ordering across all messages (which is rare), you can use a topic with a single partition, but this will limit your throughput to what a single machine can handle.
4. **Data Retention & Compacted Topics:** By default, Kafka topics retain data for a set period (e.g., two weeks). But what if you want to keep the latest value for every key indefinitely? For this, Kafka has **Compacted Topics**. In a compacted topic, each message has a key. When a new message arrives with an existing key, the old version is eventually removed. This gives you a powerful pattern: a regular topic can serve as a complete, auditable changelog (every version of an event), while a compacted topic can provide a snapshot of the latest state.
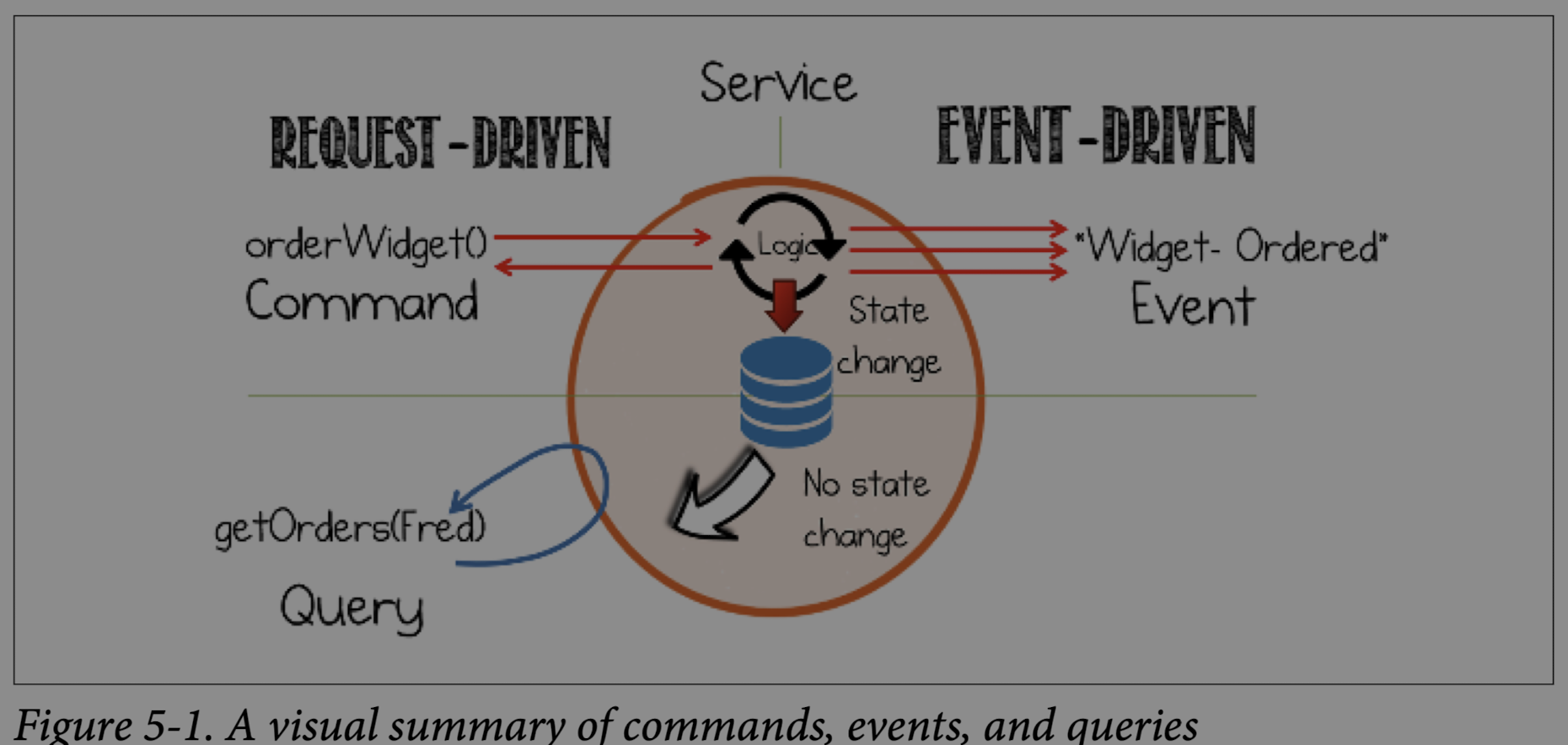
## The Language of Services: Commands, Queries, and Events
In any distributed system, services need to talk to each other. This communication generally falls into three categories:
* **Commands:** A request for another service to perform an action that changes the system's state. Think of it as a direct order: "Process this payment!" This is your classic request/response model.
* **Queries:** A request to look something up without changing any state. For example, "Get user details for ID 123."
* **Events:** These are notifications or facts about something that has already happened. They are one-way messages, like an announcement: "An order was placed." Events are the foundation of loosely coupled systems.
## The Power of Loose Coupling
"Loose coupling" is a term we hear a lot, but what does it mean in practice? It's a measure of how much a change in one service will impact another.
Loosely coupled systems are not a silver bullet. Tightly coupled communication (like a direct request/response call) is perfectly fine for services where the contract is stable and changes are rare. But for systems that need to evolve, loose coupling is essential. It shields services from the ripple effect of changes in their dependencies.
Events are the key enabler of this. Let's see how.
### Events for Notification: Reversing the Burden of Responsibility
Imagine a traditional e-commerce system. When a user places an order, the `Order Service` is responsible for everything that happens next. It has to call the `Inventory Service` to reserve stock, the `Notification Service` to send an email, and the `Shipping Service` to prepare for delivery.
What happens when a new `Dynamic Pricing Service` needs to know when an order is placed? You have to go back and modify the `Order Service` to add another call.
In an event-driven model, this responsibility is reversed. The `Order Service` simply publishes an `OrderPlaced` event to a Kafka topic. It doesn't know or care who is listening.
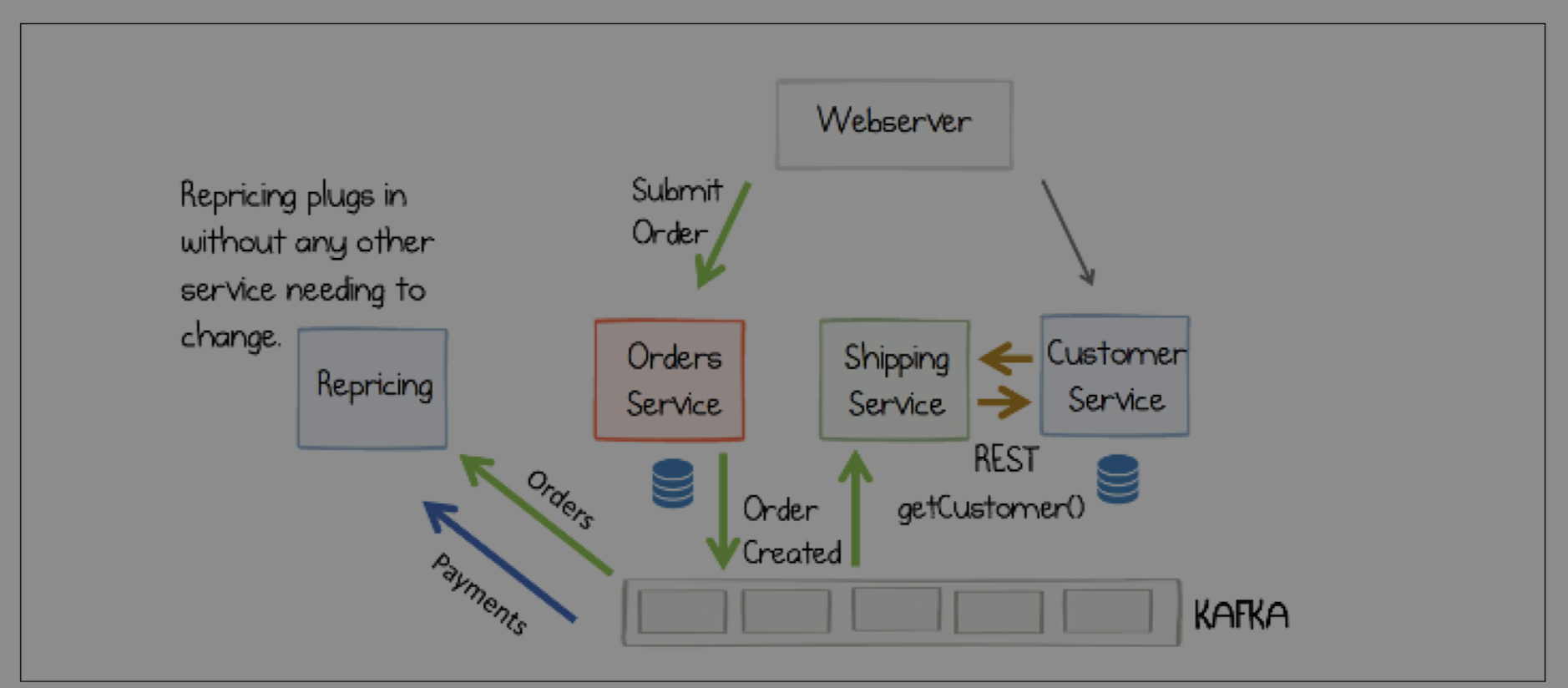
Now, the Inventory, Notification, and Shipping services simply subscribe to this event stream and react accordingly. When the new `Dynamic Pricing Service` comes along, it can just plug into the existing stream without anyone having to change the `Order Service`. This "pluggability" is a superpower for large, evolving systems.
### Events for State Transfer
Another powerful use of events is to replicate state between services. Instead of the `Shipping Service` making a direct RPC call to the `Customer Service` every time it needs a customer's address, it can subscribe to a stream of `CustomerUpdated` events.
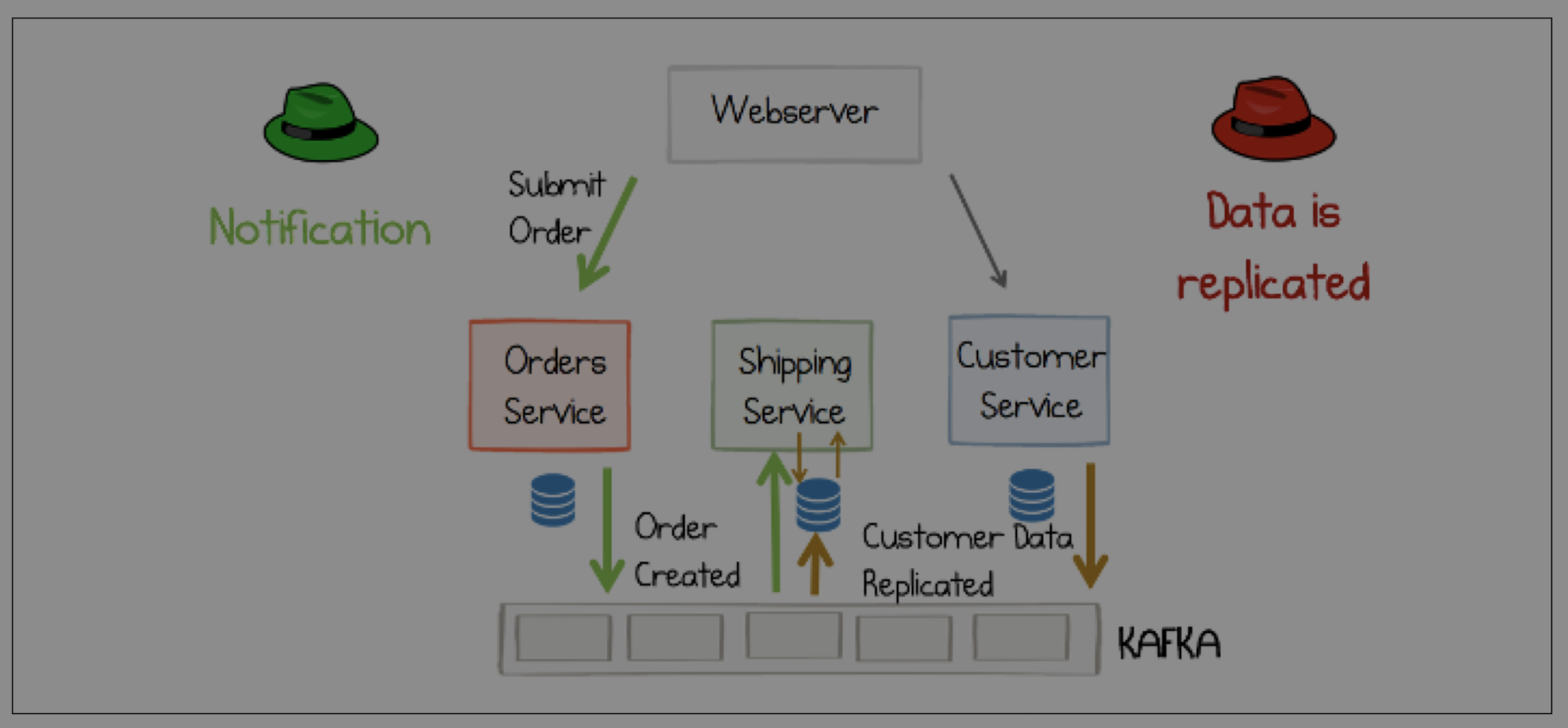
The `Shipping Service` can then maintain its own local copy of customer data, in a format that is optimized for its own needs. This makes the `Shipping Service` more resilient (it can function even if the `Customer Service` is down) and more performant (it's reading from its own database).
## Orchestration vs. Choreography: Who's in Charge?
This leads us to two overarching patterns for managing workflows that span multiple services: Orchestration and Choreography.
### Orchestration: The Conductor
In an orchestrated system, a single, central service acts as a conductor. It controls the entire workflow, telling each service what to do and when.
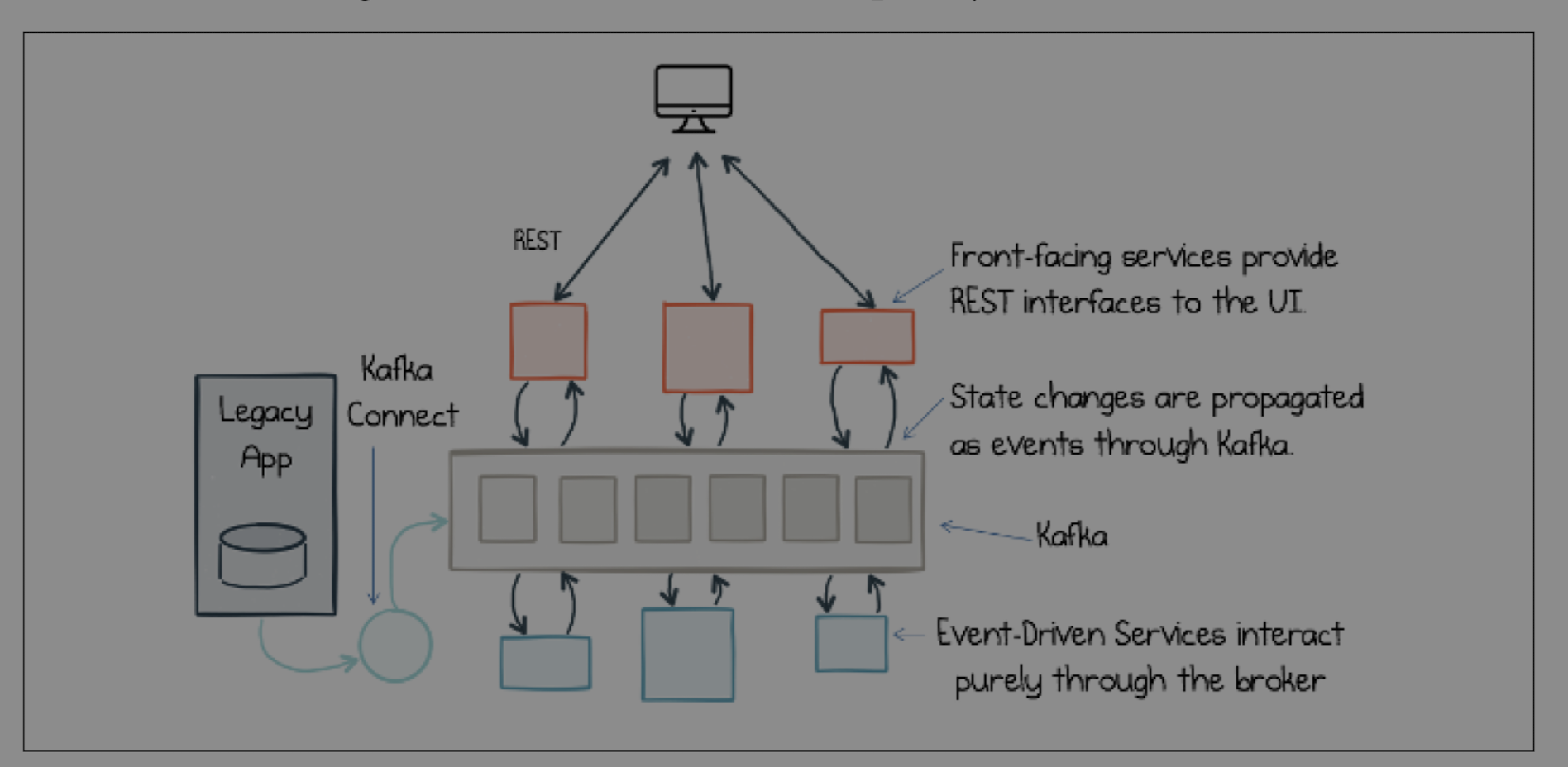
* **Pros:** The entire workflow is defined in one place. This makes it easy to understand, reason about, and debug. The logic is explicit.
* **Cons:** The orchestrator can become a central bottleneck and a single point of failure. It creates tight coupling; the orchestrator needs to know about every service it commands.
### Choreography: The Dancers
In a choreographed system, there is no central conductor. Each service knows its own small part of the process. It listens for events from other services, does its work, and then emits its own events.
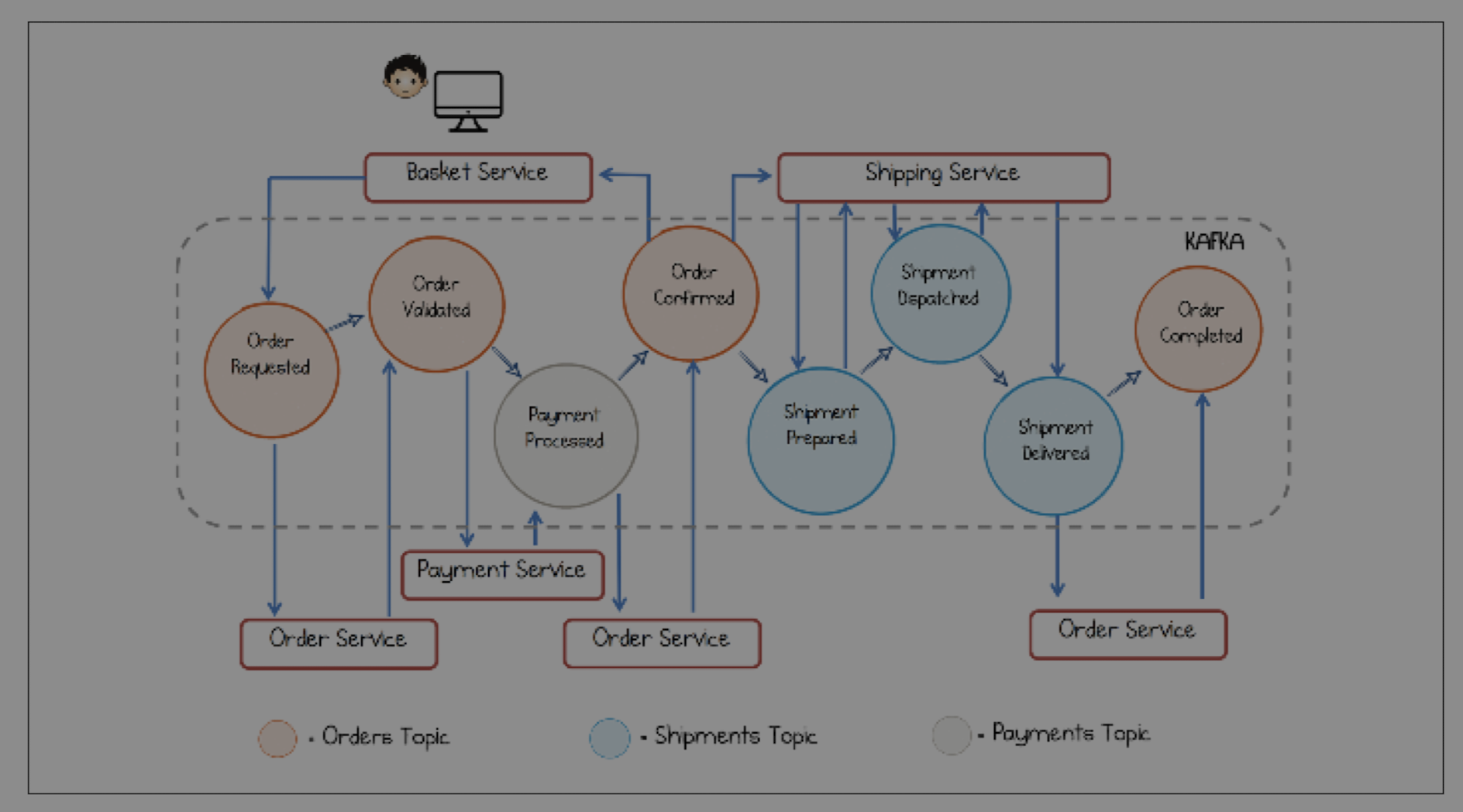
* **Pros:** This is the epitome of loose coupling and pluggability. Services are independent and can be developed, deployed, and scaled separately. The system is highly resilient.
* **Cons:** The overall workflow is not defined in any single place. It's an emergent property of the system, which can make it difficult to understand and monitor the end-to-end process.
## Finding the Right Balance
No system is purely one or the other. The reality is that most complex systems use a mix of approaches.
Within a single team or a bounded context, services might use a mix of request/response and event-driven communication. However, when communicating *between* different teams or departments working on independent domains, event-driven communication becomes the standard.
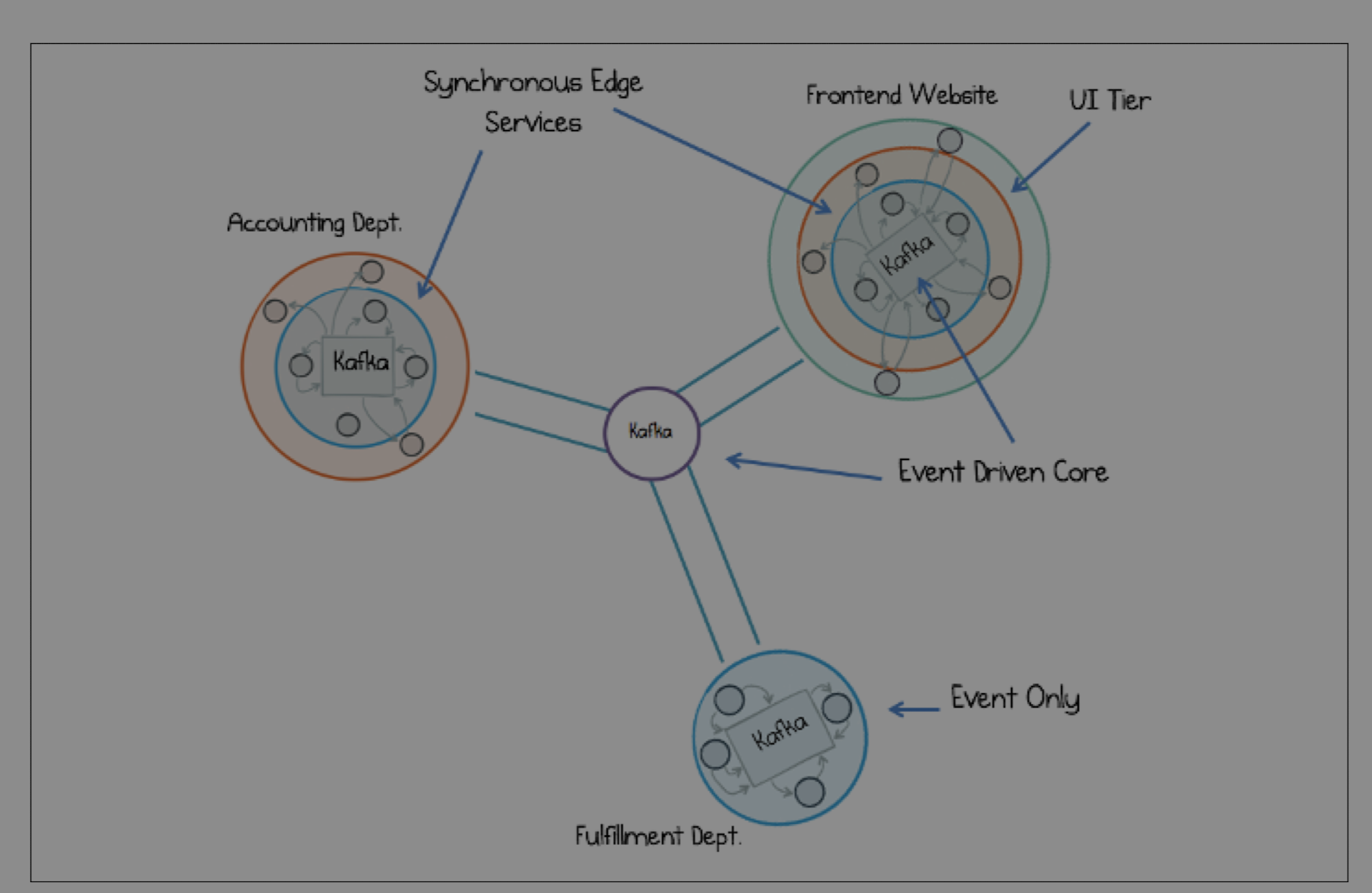
This allows each department to evolve its internal services freely while maintaining a stable, loosely coupled contract with the rest of the organization.
By understanding these fundamental patterns, we can make more informed decisions about how to design systems that are not only powerful and scalable but also resilient and adaptable to the inevitable changes of the future.
#Designing Event Driven Systems #Event-Driven Systems #Kafka #Microservices #System Design #Orchestration #Choreography #Distributed Systems #Software Architecture #Confluent