

Distributed Locks - Naive
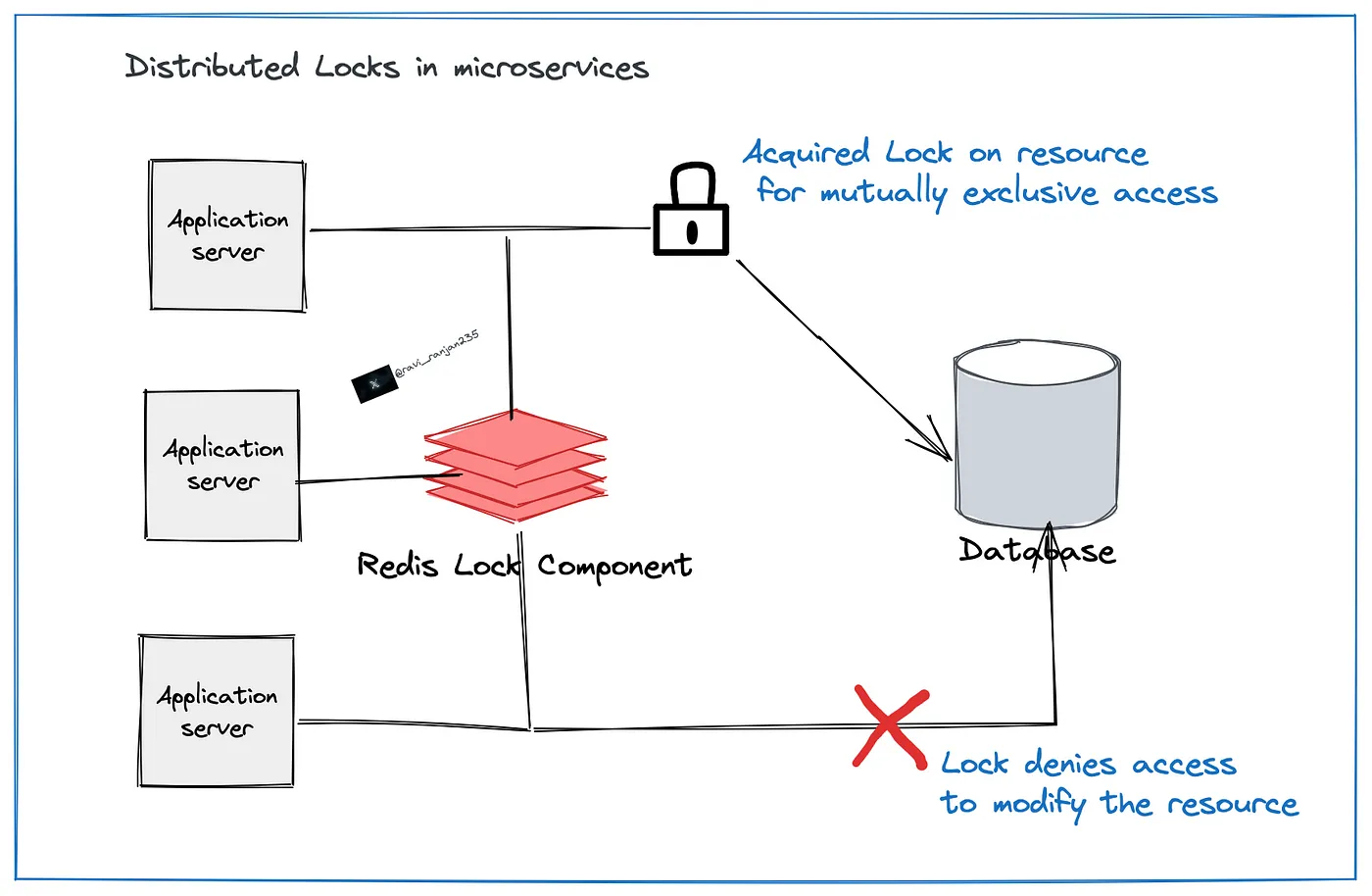
Locks are used by processes to acquire exclusive access to resource which are shared among many processes. Exclusive access is required to prevent race conditions which hard debug and nightmare to detect.
Imagine scenario of an admin is updating an email group by uploading a file. The process works like this:
All existing users in the group are removed. New users listed in the file are added in batches (e.g., 10,000 at a time). Seems straightforward, right? But now, consider what happens if another file is uploaded while the first one is still being processed.
Processing File 1: Existing users are removed. New users from File 1 are being added. File 2 is uploaded mid-way: A new process starts. It removes the current users in the email-group, which now includes users from File 1 that are being added by file1 process. Then, it starts adding users from File 2. At this point, both processes are running:
File 1 is still adding its users. File 2 is also adding its users. By the end, the email group will contain users from both files, which is incorrect because only the users from the second file should be in the group.
In our simple example — solution is simple for admin upload file2 again when issue is detected. But this is unacceptable since problem might go unnoticed for long time and in more likely scenario the problem might not be as simple to fix.
Solution? Don’t let multiple processes to start at the same time which work on same email-group. This is done by distributed locks.
Efficient and easy way to implement distributed lock requires using db such as mongo or Postgres which supports unique index. Create a collection say locks. The documents in the collection will have this schema
{
"resource_name": "resource_name", // Unique identifier for the lock
"lock_owner": "instance_id", // Identifier for the process holding the lock "expires_at":
"ISODate" // Time when the lock expires
}
Fields above are self-explanatory.
Indexes give this collection is actual behaviour. resource_name field will have unique index so that atmost only single document (and thus process) will have access to resource and ttl-index on expires_at so that in the event process fails to unlock (delete the document in this case) then document will be removed after certain time and thus prevent permanent lock on resource.
When any process wants to act on any resource say email-group it will first acquire lock on the resource, if successful continue otherwise fail gracefully.