

Storing Values within Index
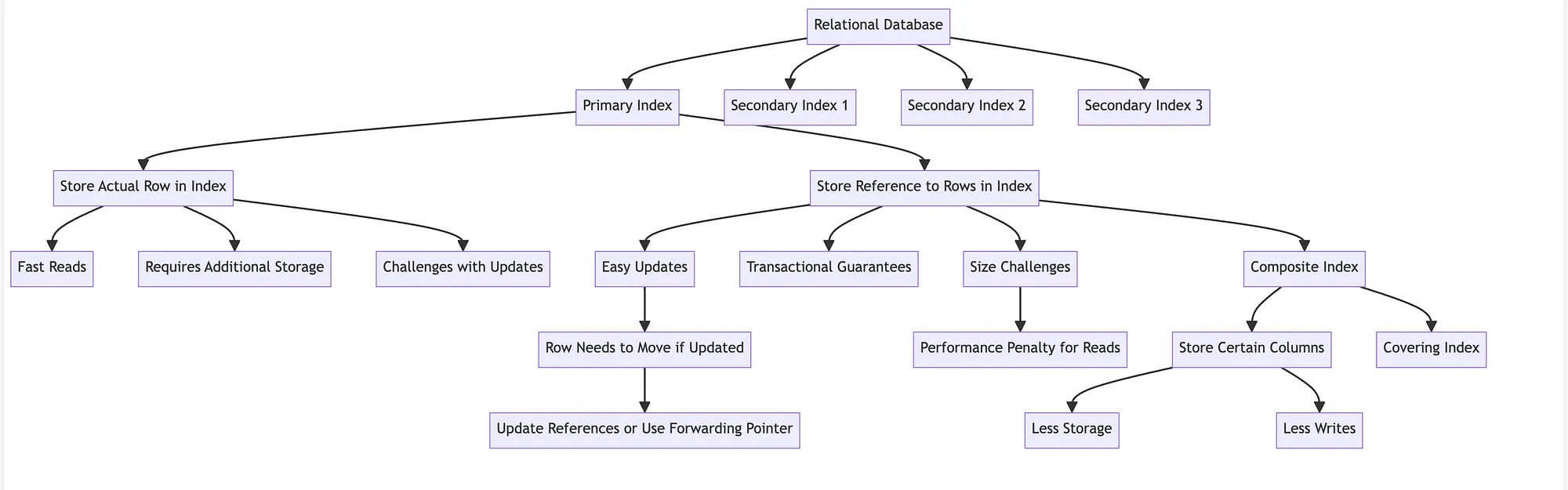
Relational databases can have one primary index and any number of secondary indexes. When queries uses indexes they use keys in the index to find values. There are two ways to have values
- Store actual row in index
- Store reference to rows in index
Storing references to rows in index is a good when there are any secondary indexes. In this way when a value needs to be updated in row, it can be updated in one place and all the indexes can refer to that one value. Also transactional guarantees are easy to implement in this case. However, challenges may arrive when size of updated row is much larger then original row size that it cannot fit in its current heap location, in which case, row need to move to new location in heap. This requires either updating references in all secondary indexes to new location or leaving a forwarding pointer behind. In normal cases, however, hopping from indexes to heap for reads is too much of performance penalty.
Other way is to storing the row in index itself, this is called clustured index. Queries use keys in the index to find the values which are stored in index it self, resulting in fast reads. This requires additional storage. When there are more than one secondary indexes, storing row in each index poses additional challenge. When value in row needs to be updated, it needs to update in many places, this requires additional efforts and resources from database to maintain transactional guarantees.
Compromise between above two case is called composite index, instead of storing complete row in an index only certain columns are added to index. Queries dealing this columns in the index can use only the index to answer the query (covering index). This requires relatively less additional storage. Relatively less writes.